NVIDIA משיקה את Nemotron 3 Ultra: MoE open בגודל 550B ל-agents שרצים לאורך זמן
Nemotron 3 Ultra הוא מודל הדגל הפתוח של NVIDIA — מערכת Mixture-of-Experts בגודל 550B פרמטרים שמשלבת שכבות Mamba (state-space) ושכבות attention בארכיטקטורה היברידית. מטרת התכנון היא יעילות עבור עומסי עבודה של agent בטווח ארוך: שמירה על דיוק גבוה תוך קיצוץ העלות וה-latency של context ארוך.
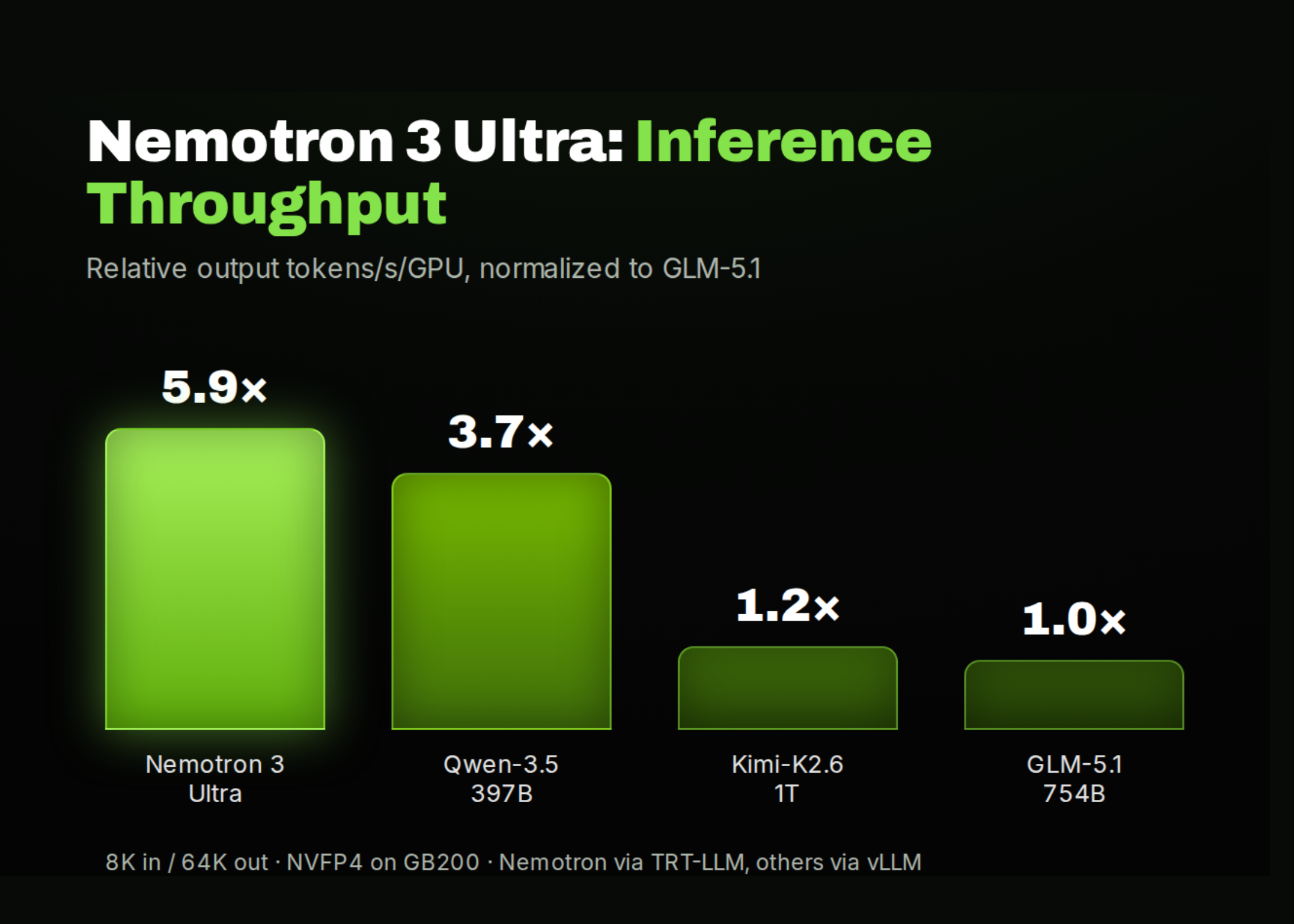
טענות הביצועים המרכזיות הן יתרון תפוקת inference של עד פי 6 על פני LLMs פתוחים דומים ברמת דיוק דומה, חלון context של מיליון token, וציון מוביל באי-הזיות (non-hallucination) של 78.7 ב-benchmark של AA-Omniscience. הגישה ההיברידית של Mamba-Attention היא מה שמאפשר את הזינוק בתפוקה — שכבות state-space מתרחבות טוב יותר עם אורך הרצף מאשר attention טהור.
אסטרטגית, שחרור מודל פתוח מוביל משרת את העסק האמיתי של NVIDIA: מכירת GPUs. מודל פתוח ויכולתי הממוטב לחומרה של NVIDIA מגביר את הביקוש ל-inference על השבבים שלה. השחרור גם מרחיב את ה-Nemotron Coalition, שכוללת כעת את Mistral, Cursor, LangChain, Perplexity, Nous Research ו-Prime Intellect.
המודל נחת על 313 נקודות ב-r/LocalLLaMA עם עניין רב במשקלי ה-BF16 הפתוחים, אם כי ב-550B פרמטרים deploy מקומי הוא מחוץ להישג ידם של רוב המשתמשים. שווה לעקוב אחר benchmarking עצמאי של טענת התפוקה פי 6 ואיך היא ניצבת מול DeepSeek V4 ו-Qwen3.7-Max במשימות agent.