OpenAI2026-05-04
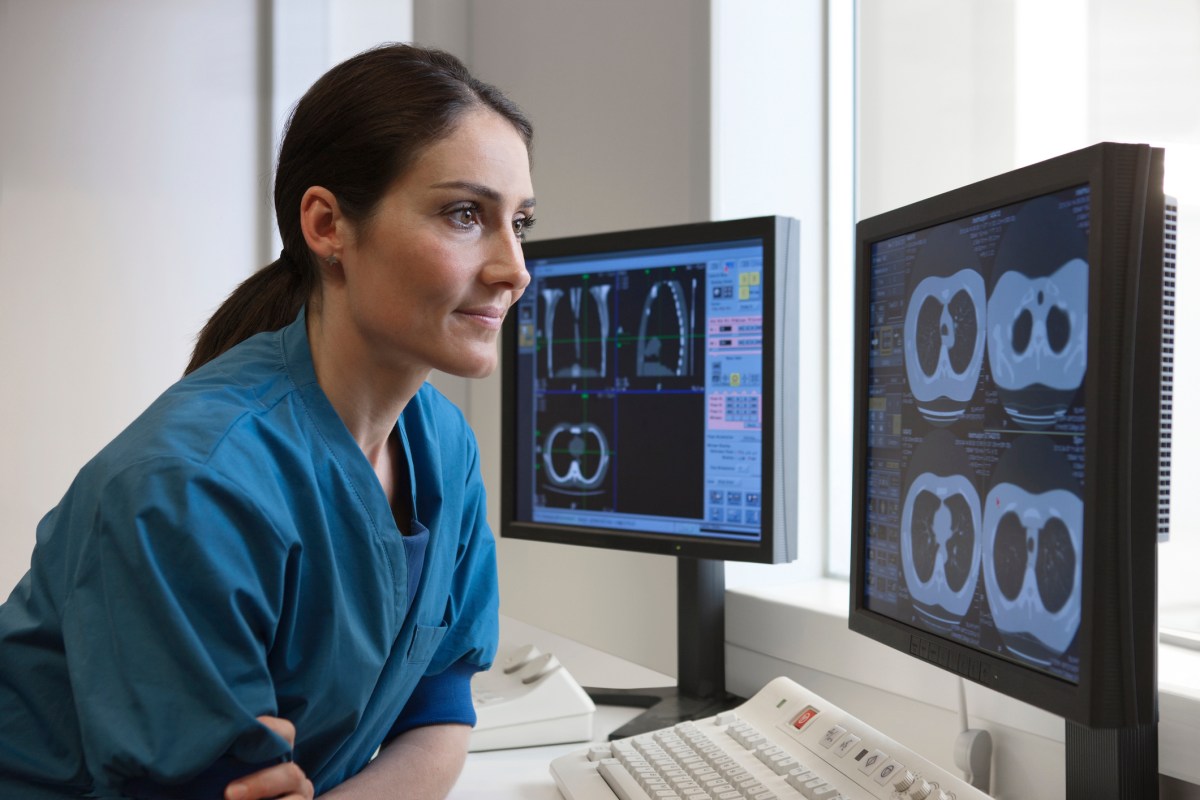
מחקר Harvard: o1 עוקף רופאי מיון עם 67% דיוק אבחנתי מול 50–55%
ניתוח AI
ניסוי בהרווארד מצא שמודל o1 של OpenAI אבחן נכון 67% מהמקרים בחדר מיון, לעומת 50-55% אצל רופאי טריאז'. המחקר בוחן LLMs חזיתיים במגוון הקשרים רפואיים ומלבה מחדש את הדיון סביב deployment קליני.