Liquid AI משיקה את LFM2.5-8B-A1B: MoE על המכשיר עם context של 128K
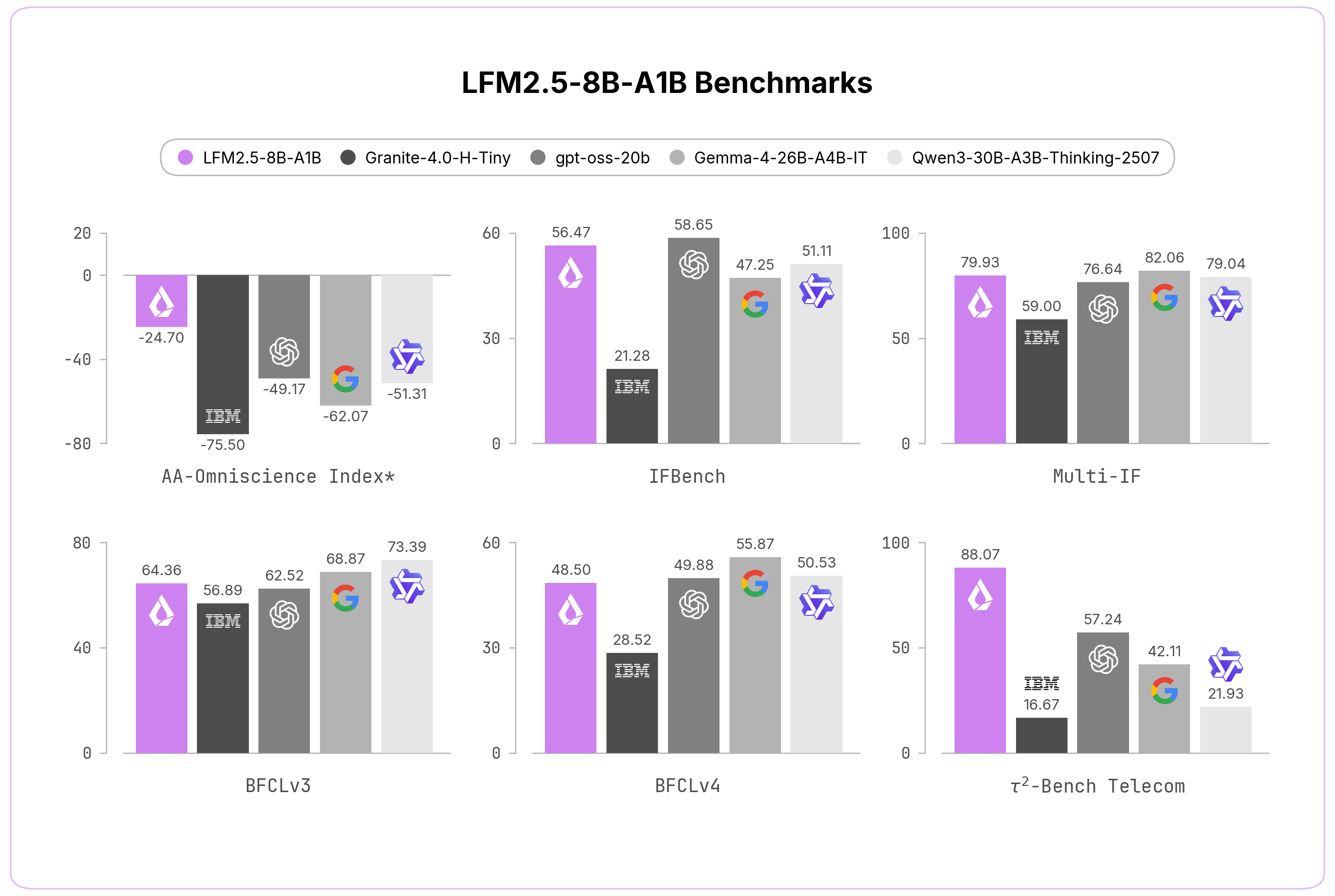
המודל LFM2.5-8B-A1B של Liquid AI, שזמין כעת ב-Hugging Face, הוא מודל Mixture-of-Experts משופר להרצה on-device ששדרג באופן משמעותי את קודמו LFM2-8B-A1B. השיפורים המרכזיים: חלון context מורחב של 128K, pretraining שהורחב מ-12 טריליון ל-38 טריליון tokens, ושילוב reinforcement learning בקנה מידה גדול לחידוד ביצוע הוראות ושימוש בכלים.
שינוי הנדסי בולט הוא הכפלת אוצר המילים כדי לשפר את יעילות ה-tokenization בשפות שאינן לטיניות — ניצחון מעשי עבור deployment רב-לשוני, שבו ניפוח ה-tokens מנפח עלות ו-latency. התוצאה היא מודל שמסוגל לשרשר tool calls ולבצע משימות מורכבות תוך הרצה יעילה על laptops ברמת כניסה — ההבטחה המרכזית של תחום ה-on-device.
המיצוב חשוב בשבוע שנשלט על ידי frontier models בסדר גודל של טריליוני פרמטרים וחרדת עלויות: LFM2.5 תוקף את הקצה ההפוך, שבו הרצה מקומית מבטלת עלויות API per-token ושומרת את הנתונים on-device. הוא מתחרה במודלים קטנים ויעילים של Qwen, בקו ה-Phi של Microsoft וב-Gemma של Google, וזירת r/LocalLLaMA הפעילה השבוע (StepFun 3.7 Flash, threads של self-benchmarking) מראה תיאבון חזק למודלים מקומיים יכולתיים. ההסתייגות היא תקרת היכולת המובנית — מודל MoE on-device ממשפחת 8B לא ישתווה ל-Opus 4.8 או ל-GPT-5.5 ב-reasoning קשה, כך שהערך שלו הוא התאמה למשימה ולא ביצועי frontier.