NVIDIA2026-05-03
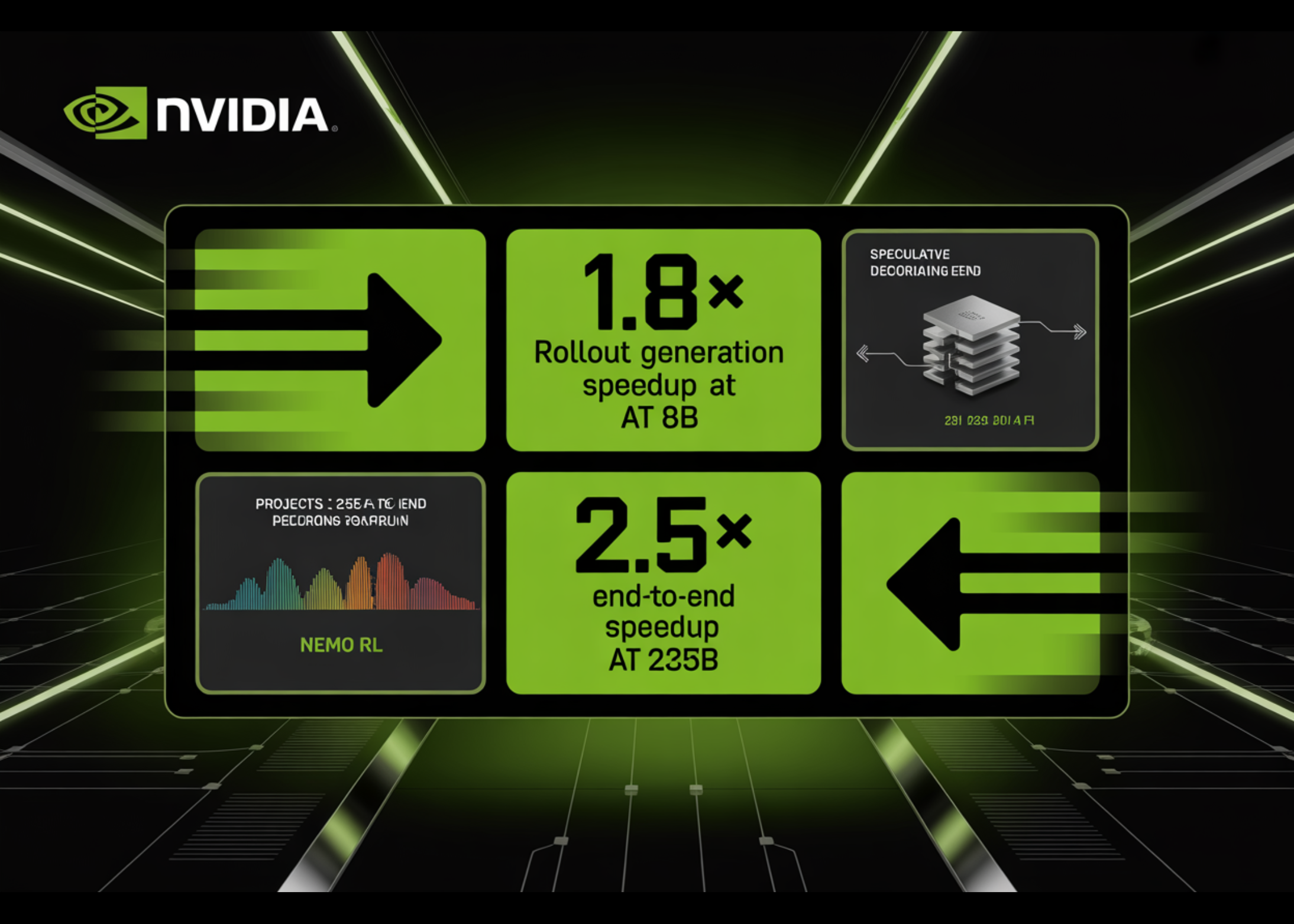
NeMo RL מוסיף speculative decoding לזירוז rollout פי 1.8 ב-8B
ניתוח AI
NVIDIA Research שילבה speculative decoding ישירות ב-NeMo RL עם backend של vLLM, ומספקת האצה של 1.8x ללא הפסדים בגודל 8B פרמטרים, עם תחזית להאצה end-to-end של 2.5x במודלים בקנה מידה של 235B.