NVIDIA releases Nemotron 3 Ultra, an open 550B MoE hybrid Mamba-Transformer for long-running agents
Nemotron 3 Ultra is NVIDIA's flagship open model release, a 550B-parameter Mixture-of-Experts system that combines Mamba (state-space) and attention layers in a hybrid architecture. The design goal is efficiency for long-horizon agentic workloads: keeping accuracy high while cutting the cost and latency of long context.
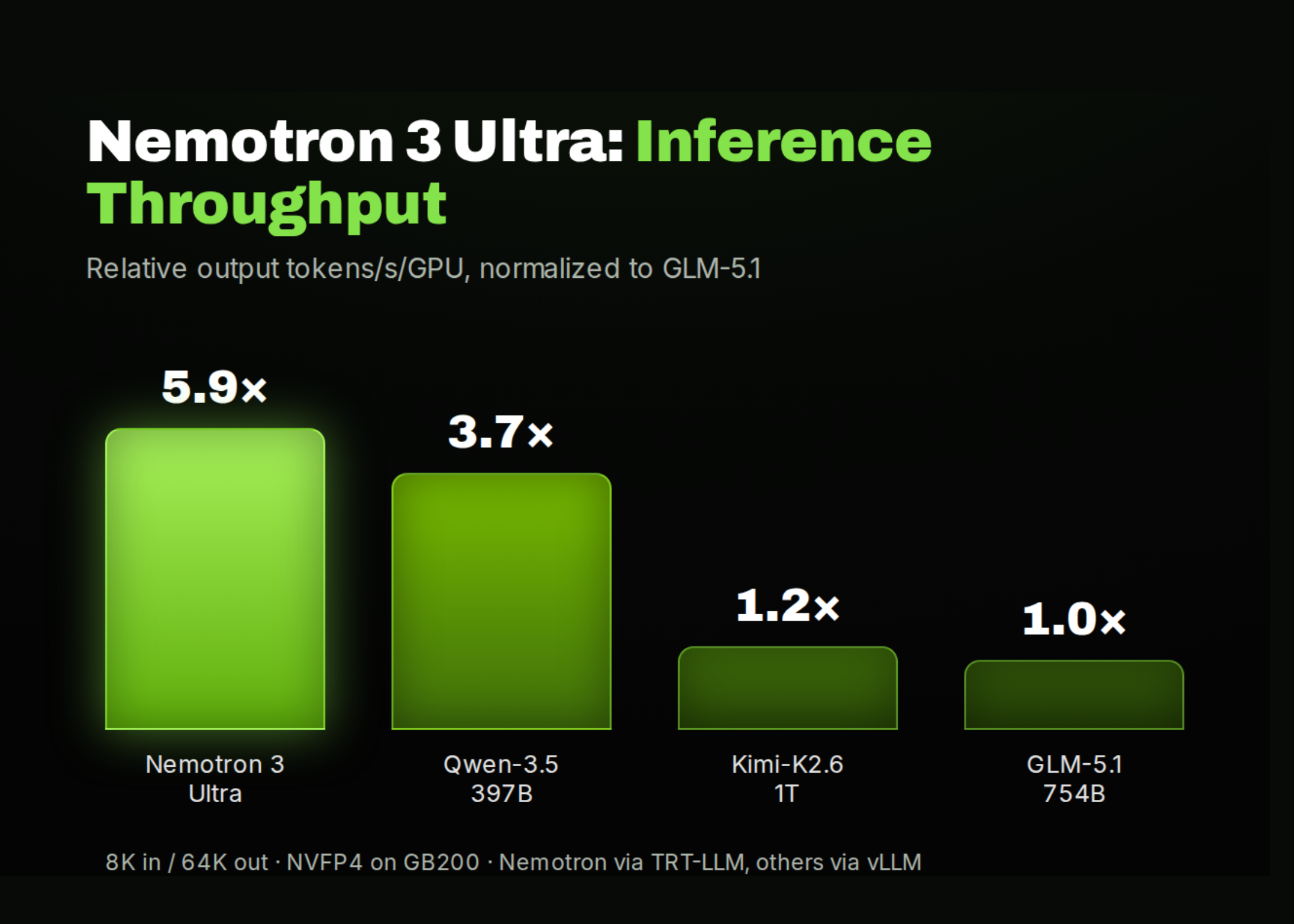
The headline performance claims are an up-to-6x inference throughput advantage over comparable open LLMs at similar accuracy, a 1-million-token context window, and a best-in-set non-hallucination score of 78.7 on the AA-Omniscience benchmark. The hybrid Mamba-Attention approach is what enables the throughput gains — state-space layers scale better with sequence length than pure attention.
Strategically, releasing a top open model serves NVIDIA's real business: selling GPUs. A capable open model optimized for NVIDIA hardware drives more inference demand on its chips. The release also grows the Nemotron Coalition, which now includes Mistral, Cursor, LangChain, Perplexity, Nous Research and Prime Intellect.
The model landed at 313 points on r/LocalLLaMA with strong interest in the open BF16 weights, though at 550B parameters local deployment is out of reach for most. Watch independent benchmarking of the 6x throughput claim and how it stacks against DeepSeek V4 and Qwen3.7-Max on agentic tasks.