Liquid AI ships LFM2.5-8B-A1B on-device MoE with 128K context
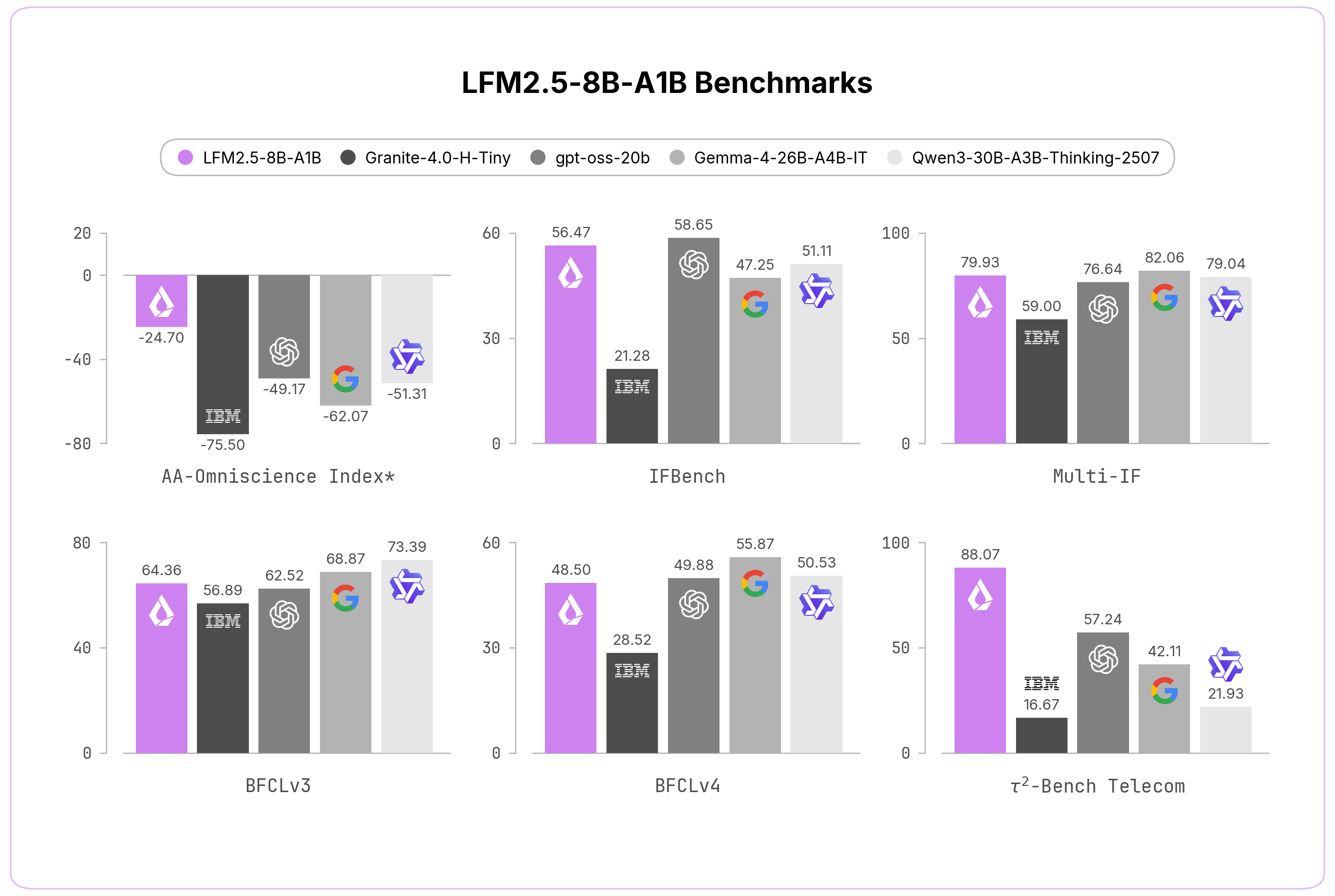
Liquid AI's LFM2.5-8B-A1B, now on Hugging Face, is an enhanced on-device Mixture-of-Experts model that meaningfully upgrades its predecessor LFM2-8B-A1B. The key improvements: an expanded 128K context window, pretraining scaled from 12 trillion to 38 trillion tokens, and the integration of large-scale reinforcement learning to sharpen instruction-following and tool use.
A notable engineering change is doubling the vocabulary to improve tokenization efficiency for non-Latin languages — a practical win for multilingual deployment where token bloat inflates cost and latency. The result is a model that can chain tool calls and accomplish complex tasks while running efficiently on entry-level laptops, the core promise of the on-device segment.
The positioning matters in a week dominated by trillion-parameter frontier models and cost anxiety: LFM2.5 attacks the opposite end, where local execution eliminates per-token API costs and keeps data on-device. It competes with small efficient models from Qwen, Microsoft's Phi line and Google's Gemma, and the active r/LocalLLaMA scene this week (StepFun 3.7 Flash, self-benchmarking threads) shows strong appetite for capable local models. The caveat is the inherent capability ceiling — an 8B-class on-device MoE won't match Opus 4.8 or GPT-5.5 on hard reasoning, so its value is task-fit rather than frontier performance.