DeepSeek AI News
Every AI news story AI Briefing has published about DeepSeek — 41 articles spanning Apr 18, 2026 – Jun 21, 2026. Track DeepSeek's model releases, research papers, product launches, funding rounds, and partnerships across the AI industry, updated daily.
41 articles · Apr 18, 2026 – Jun 21, 2026DeepSeek V4 Flash drives China's lead in global AI token usage
DeepSeek's V4 Flash was reported as the world's most-used model at 4.63 trillion tokens, helping position China as the leader in global AI token usage. The model leverages cheaper energy and highly efficient design to undercut leading US AI companies on cost, signaling a growing competitive advantage for Chinese firms.
2026-06-21

DeepSeek raises ~$7.4B in first external round with investor no-poaching clause
DeepSeek completed its first external funding round of roughly $7.4 billion (50 billion yuan), valuing the company at $50–59 billion — China's most valuable AI-exclusive startup. Founder Liang Wenfeng committed 20 billion yuan and imposed a no-poaching clause barring investors from recruiting employees. Backers include Tencent, CATL, and the National AI Industry Investment Fund.
2026-06-21
DeepSeek raises record $7.4B at ~$52B valuation as US holds off blacklisting
Chinese AI lab DeepSeek closed a record $7.4B first funding round from Tencent (~10B yuan), CATL (~5B yuan), and China's National AI Fund, with founder Liang Wenfeng adding 20B yuan personally—valuing the company at $52–59B. On June 16 the US elected not to add DeepSeek to a trade blacklist despite interagency approval, aiming to reduce tensions with Beijing.
2026-06-18

DeepSeek Cuts V4 Pro Prices 75%, Igniting a Chinese AI Pricing War
DeepSeek slashed its flagship V4 Pro pricing by 75% — to $0.0036 per 1M input tokens and $0.87 per 1M output tokens — positioning it as a global leader in performance-per-dollar and forcing rivals and Chinese cloud providers to recalibrate pricing as a funding round looms.
2026-06-15

DeepSeek's 75% V4 Pro price cut makes it the leader in AI performance-per-dollar
DeepSeek announced a permanent 75% price cut for its flagship V4 Pro model, dropping the API price to $0.0036 per million input tokens. Enabled by China's domestic AI chip supply chain, the move makes V4 Pro the global leader in 'AI performance efficiency per dollar' per Artificial Analysis, undercutting GPT-5.5 and pushing DeepSeek to the top of OpenRouter's weekly token usage.
2026-06-12

DeepSeek reportedly completes major training run on Huawei chips, bypassing Nvidia
Chinese researchers, working with Huawei and Shenzhen institutions, reportedly completed full-parameter post-training of DeepSeek's ~1.6-trillion-parameter V4-Pro model using over 1,000 Huawei Ascend 910C chips, without any Nvidia hardware. The milestone signals that domestically produced accelerators can support intensive training-class AI workloads, a notable advance for China's AI hardware independence.
2026-06-11

DeepSeek tops Ramp's trending-vendors index as US firms route data to its cheaper V4 API
DeepSeek ranked No. 1 on Ramp's June 2026 trending software-vendors index, signaling a jump in US business adoption. The surge is driven by cost: DeepSeek V4 offers far lower API pricing than rivals, prompting US firms to pay it directly and route data through its platform despite security warnings.
2026-06-09

DeepSeek tops trending-vendor list as US firms start paying directly
DeepSeek topped Ramp's trending software-vendors list for June 2026 as American companies, for the first time, make direct payments for its AI services rather than self-hosting its open-source models. The shift signals growing corporate demand for affordable AI alternatives, even as DeepSeek's V4 model trails top Western systems in overall performance. Cost-effectiveness is the dominant draw.
2026-06-08

Huawei Ascend chips complete full-parameter post-training of DeepSeek-V4
A research team including Huawei says it used Ascend 910C chips to complete full-parameter post-training of the 1.6-trillion-parameter DeepSeek-V4-Pro model on a cluster of at least 1,000 Huawei chips — a major step for China's AI self-reliance as it moves from inference to the harder task of training amid US sanctions.
2026-06-07

DeepSeek nears $7.4B funding round from Tencent and CATL, targeted to close June 11
DeepSeek is finalizing a ¥50 billion (~$7.4 billion) round from investors including Tencent and battery maker CATL, earmarked for frontier model development and infrastructure expansion. The round is targeted to close June 11, positioning DeepSeek among the largest capital recipients in the AI race.
2026-06-06
1.6 trillion-parameter DeepSeek model demoed running on a MacBook M5 Max via SSD
A 1.6 trillion-parameter DeepSeek model, likely a variant of DeepSeek v4 PRO, was demonstrated running on a MacBook M5 Max using SSD-backed memory. The demo highlights growing portability of frontier-scale models on consumer hardware and progress in optimizing large models for efficient local inference without cloud infrastructure.
2026-06-05

Hong Kong launches DeepSeek-based HKGAI-V3 optimized for domestic chips
The Hong Kong Generative AI R&D Centre launched HKGAI-V3, a large language model built on DeepSeek V4 and optimized to run on domestic chips. It claims over tenfold token compression and a near-hundredfold increase in uninterrupted agent runtime, with an AI agent platform running stably for up to 28 hours.
2026-06-04

DeepSeek permanently cuts flagship model API price by 75%
Chinese AI startup DeepSeek announced a permanent 75% reduction in the API price of its flagship model, effective June 1. The aggressive pricing is generating debate across the global AI industry, with analysts suggesting it could pressure AI infrastructure development and reignite the price-performance war among model providers.
2026-06-02

DeepSeek makes 75% V4-Pro price cut permanent, adds 90% cached-token discount
DeepSeek made its temporary 75% V4-Pro API discount permanent and stacked a 90% cut on cached tokens, putting its frontier reasoning model at roughly one-quarter the cost of comparable OpenAI or Anthropic tokens. The move sharply escalates the global pricing war ahead of summer US model releases.
2026-05-28

DeepSeek cuts V4-Pro API pricing 75% to $0.87 per 1M output tokens
DeepSeek announced a permanent 75% price cut for its V4-Pro model, dropping API access to $0.0036 per 1M cached input tokens and $0.87 per 1M output tokens — a direct cost-leadership shot at OpenAI, Anthropic and Meta. The cut reignited the 'American AI bubble' narrative across Reddit and HN, with one r/OpenAI thread hitting 1,222 upvotes.
2026-05-27

DeepSeek makes 75% V4-Pro price cut permanent, escalating the global AI pricing war
DeepSeek confirmed its 75% discount on flagship V4-Pro is permanent, with API pricing as low as $0.003625 per million tokens — roughly 100x cheaper than GPT-5.5's $30/M output tokens. The company attributes the cut to genuine efficiency gains in long-context inference, not a promotion, and is reportedly preparing a new funding round.
2026-05-26

DeepSeek makes 75% V4-Pro price cut permanent, repricing intelligence-per-dollar
Chinese AI startup DeepSeek confirmed it will permanently maintain a 75% discount on its flagship V4-Pro model, lowering API pricing to between 0.025 and 6 yuan per million tokens. The move positions V4-Pro among the world's best on an intelligence-per-dollar basis and reflects a broader push to reduce dependence on NVIDIA hardware via domestic alternatives.
2026-05-25
DeepSeek makes V4-Pro/Flash discount permanent
DeepSeek announced its API discount is now permanent, locking in lower pricing for DeepSeek-V4-Pro (1.6T total / 49B active params, 1M context) and V4-Flash (284B total / 13B active params). The move cements DeepSeek's positioning as the price leader in the frontier-class API tier, just as Alibaba pulls Qwen's top models behind a paid wall.
2026-05-23

DeepSeek to Launch Intelligent Agent Products, Doubling Down on Agentic AI
DeepSeek is preparing to launch intelligent agent products, embracing the vision of AI engineering evolving toward building complete agent operating environments. The company previously released a preview of its V4 large language model on April 24, highlighting strong performance in agentic coding benchmarks — and is now productizing that capability.
2026-05-21
DeepSeek V4 Flash and V4 Pro ship with 1.6T-param agentic-coding tier
DeepSeek released V4 Flash and V4 Pro models, continuing its price-performance push. V4 Flash is an efficiency-optimized MoE for speed and high-volume pipelines; V4 Pro has 1.6 trillion total parameters and targets deep reasoning and multi-step agentic coding. The split mirrors the industry trend of Pro/Flash tiers over single broad base models.
2026-05-20

DeepSeek-V4-Flash and V4-Pro released as open-weight models with hybrid attention and 13B active params
DeepSeek released V4-Flash (284B total / 13B active parameters) and V4-Pro as open-weight models on Hugging Face. Both are optimized for agentic coding and long-context efficiency, with structural innovations including hybrid attention and DeepSeek Sparse Attention to reduce compute and memory costs. V4-Flash is positioned as a cost-effective option for developers building long-context and agentic workflows.
2026-05-18

DeepSeek-V4 Pro (1.6T-A49B MoE) and V4 Flash released as open weights
DeepSeek released its V4 series on Hugging Face, including a 1.6T-A49B MoE Pro version and a 284B-13B Flash version. The Flash model is noted for strong performance relative to size and architectural changes that improve and cheapen long-context capabilities.
2026-05-17

DeepSeek previews V4: 1.6T params, 1M context, 75% API price cut
DeepSeek-V4 preview ships with 1.6T total / 49B active MoE parameters, a 1M-token context window, and a 10x smaller KV cache tuned for agentic workloads. A V4-Flash variant offers 284B/13B. API pricing dropped 75% and cache costs 90%; benchmarks don't meaningfully close the frontier gap.
2026-05-17

DeepSeek V4 runs on Huawei chips as Stanford HAI says US-China AI gap 'effectively closed'
DeepSeek's V4 model preview runs on Huawei-designed chips rather than Nvidia, signaling reduced Chinese dependence on US chipmakers. A Stanford Institute for Human-Centered AI report concludes the performance gap between top US and Chinese AI models has 'effectively closed,' with DeepSeek V4 explicitly optimized for cost-efficiency on widely available hardware.
2026-05-15

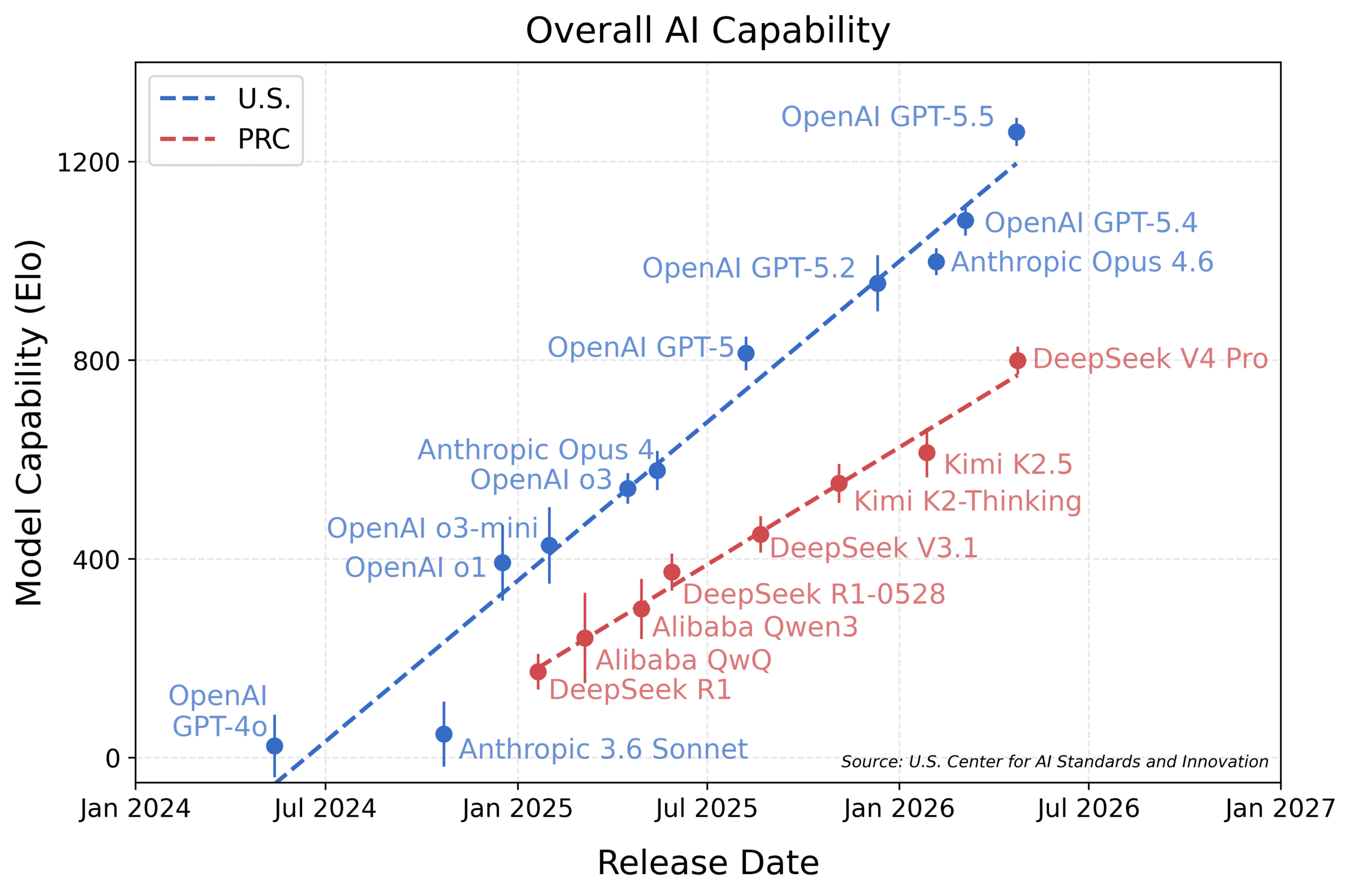
DeepSeek V4 nears GPT-5-level performance per US CAISI evaluation
DeepSeek V4 (1.6T params, MIT license) was evaluated by the U.S. AI Standards and Innovation Center as performing similarly to OpenAI's GPT-5 (Aug 2025), making it the best Chinese AI model — though still trailing the newest U.S. models by ~8 months. Cost efficiency was a noted strength.
2026-05-14
DeepSeek V4-Pro: 1.6T params, 1M-token context, sharply lower inference cost — reportedly forces Anthropic price cut
DeepSeek released V4 via API on April 24, 2026, with a Pro variant carrying 1.6 trillion total parameters and a 1 million token context window. V4-Pro requires substantially less inference FLOPs and KV-cache than V3.2, making it competitive for agentic loops and large-codebase workloads. The release has stirred AI economics, with Anthropic reportedly cutting Opus 4.7 prices in response, and DeepSeek separately optimizing the model for Huawei chips.
2026-05-13

DeepSeek V4-Pro hits 150+ tok/sec/user on GB200 NVL72, rivals frontier at fraction of cost
DeepSeek V4-Pro, released via API on April 24, packs 1.6 trillion total parameters and a 1M-token context window, and delivers 150+ tokens/sec/user on NVIDIA's GB200 NVL72 platform. It reportedly rivals Claude Opus 4.7 and GPT-5.5 in coding-heavy agentic workflows at a small fraction of the cost, and V4 was reportedly trained for $7.8M.
2026-05-11

DeepSeek V4 breaks the math on $500B in AI capex; Anthropic cuts Opus 4.7 pricing 67%
DeepSeek V4 Pro (1.6T total parameters, 49B active per token via MoE, 1M token context) launched via API on April 24 and requires only 27% of V3.2's single-token inference FLOPs and 10% of its KV cache at full context. The efficiency gains are pushing down API pricing industry-wide — Anthropic cut Claude Opus 4.7 prices 67% post-V4 launch.
2026-05-11
Chinese chipmakers integrate DeepSeek V4 across domestic hardware
Chinese semiconductor manufacturers including Huawei and Cambricon are rapidly integrating DeepSeek's V4 LLM across domestic platforms. Huawei adapted V4 to its Ascend 950PR chip, reportedly achieving 2.87x single-card inference performance vs NVIDIA's H20 and a 60% improvement in multimodal generation efficiency at lower deployment cost.
2026-05-09

DeepSeek closes in on $45B valuation in round led by China's Big Fund with Tencent and Alibaba
DeepSeek is closing a funding round at nearly $45B — roughly 4x its valuation two weeks earlier — led by the China Integrated Circuit Industry Investment Fund ('Big Fund') with participation from Tencent and Alibaba. The company plans to scale compute, hire aggressively, and deepen Huawei chip compatibility to reduce NVIDIA reliance.
2026-05-07

DeepSeek V4 ships with 1M-token context and open weights as valuation jumps to $45B
DeepSeek released V4 in 'Pro' (1.6T total params) and 'Flash' (284B) variants with a 1M-token context window and open weights, optimized for agentic coding, research and document analysis. FT and Bloomberg report DeepSeek is in talks for its first VC round at a $45B valuation — up from $20B just weeks ago — and V4 was tuned for inference on Huawei's 950PR chip even though training still used NVIDIA.
2026-05-07

DeepSeek closes $50B funding round with China's national AI fund leading
DeepSeek is closing a round expected to value the Chinese AI lab at roughly $50 billion (>300B yuan), with China's national AI fund in talks to lead and Alibaba and Tencent rumored as potential co-investors. The raise underscores Beijing's strategic backing of homegrown AI as Huawei 950PR chips power V4 inference.
2026-05-06
DeepSeek V4 (1.6T params) launches at 97% below GPT-5.5 pricing, built on Huawei Ascend and Cambricon
DeepSeek released its V4 model with the V4-Pro variant featuring 1.6 trillion parameters and a 1-million-token context window, built primarily on domestic Chinese silicon (Huawei Ascend, Cambricon) rather than NVIDIA. V4 launched with aggressive pricing — 97% below OpenAI's GPT-5.5 — with API compatibility for minimal switching costs. NIST CAISI has published an evaluation, and the NYT argues DeepSeek is reshaping the structure of the global AI race.
2026-05-05

NYT: DeepSeek's latest release reshapes the US-China AI race
The NYT argues DeepSeek's newest model has not only put China level with the US but changed the nature of the race itself, via cost-efficient reasoning. CAISI separately judged DeepSeek V4 Pro the most powerful Chinese model — though still ~8 months behind US frontier.
2026-05-04

DeepSeek previews V4-Pro (1.6T) and V4-Flash with 1M context
DeepSeek released a preview of V4 in two versions: V4-Pro at 1.6T parameters and V4-Flash at 284B, both supporting 1M-token context. Open-source, MIT-licensed, with day-one vLLM support and pricing significantly below US frontier labs. Strong agentic and coding benchmarks rival closed-source frontier systems.
2026-05-01
DeepSeek V4 ships 1M context, MIT-licensed open weights — but markets shrug
DeepSeek shipped V4-Pro and V4-Flash preview models on April 24 under MIT-licensed open weights with 1M context, undercutting Western API prices by an order of magnitude. Markets responded coolly — Omdia's Lian Jye Su called the announcement predictable as architecture and efficiency gains have become widely replicated.
2026-04-30

DeepSeek V4 (1.6T params, 1M context) ships on Huawei chips with aggressive price cuts
DeepSeek released a preview of V4, its most powerful model to date — 1.6 trillion parameters, 1M-token context, trained on Huawei chips — and slashed pricing on the new flagship to undercut Western and Chinese rivals. Markets called the architectural advances 'predictable' and the launch failed to wow analysts.
2026-04-29

DeepSeek V4 ships at 1.6T params with day-0 Blackwell support and aggressive price cuts
DeepSeek released V4 in preview on April 24 with two variants: V4-Pro at 1.6T parameters and V4-Flash at 284B, both supporting up to 1M-token context and using just 27% of single-token inference FLOPs and 10% of the KV cache versus prior frontier models. NVIDIA delivered day-0 Blackwell support hitting 3,500 tokens/sec on the 1.6T model via NVFP4, while DeepSeek slashed flagship pricing to pressure US rivals — though Reuters notes markets are no longer wowed.
2026-04-28

DeepSeek V4 preview: 1.6T MoE, 1M context, Apache 2.0 — and a Huawei Ascend pivot
DeepSeek released preview V4-Pro-Max (1.6T parameters) and V4 Flash (284B) MoE models with 1M-token context, open-weighted under Apache 2.0 at API pricing of $1.74/$3.48 per million tokens. The release introduces Compressed Sparse Attention + Heavily Compressed Attention, cutting KV cache by ~10x at 1M context and using just 27% of single-token inference FLOPs vs V3.2. Crucially, DeepSeek validated fine-grained Expert Parallelism on Huawei Ascend NPUs at 1.5–1.73x speedups — a blueprint resilient to US export controls.
2026-04-27
DeepSeek V4 Launch Expected This Week with 1 Trillion Parameters
DeepSeek V4 launch is highly anticipated this week following industry insider tweets, with expectations of 1 trillion total parameters and 32-37 billion active parameters via MoE architecture. The model is optimized for Huawei chips amid US export restrictions and geopolitical tensions.
2026-04-20
DeepSeek V4 expected late April with 1 trillion parameters optimized for Huawei Ascend chips
DeepSeek V4 is anticipated in late April 2026 featuring approximately 1 trillion total parameters using Mixture-of-Experts architecture with only 32-37 billion parameters active per token. The model has missed two previous launch windows but represents the first frontier-class model optimized for Chinese domestic semiconductors after months of collaboration with Huawei and Cambricon.
2026-04-18